


Analyzing self managed Kubernetes cluster cost on AWS via Cloudhealth
There are are two main ways to use Kubernetes in the public cloud:
- Managed service — like EKS, GKE, VMware Kubernetes Engine, etc
- Self deployed Kubernetes— using PKS, Rancher, Gardner, KOPs, etc
Majority of the deployments are still self deployed, and while the installation tools are well developed, they all lack an ability to understand the utilization of AWS resources supporting Kubernetes, and ultimately the application.
Cloudhealth by VMware helps bridge this gap by allowing you to analyze the cost and utilization of all the AWS resources that are being used on AWS (or Azure or GCP) in support of your self deployed Kubernetes cluster.
In this blog, I will outline how we analyzed a simple Kubernetes cluster deployed with the opensource Kubernetes Operations (kops) tool
https://github.com/kubernetes/kops
Using my standard application (my favorite fitcycle app) and captured the related costs and utilization on AWS with Cloudhealth.
Some component basics:
A quick review of the main components used in this blog:
- Cloudhealth: provides the world’s most trusted software platform for accelerating business transformation in the cloud. More than 3,800 organizations globally rely on CloudHealth to manage over $5B in combined cloud spend, based on the platform’s ability to easily manage cost, ensure security compliance, improve governance and automate actions across multi-cloud environments. Known for offering the highest levels of data integrity throughout an organization’s entire cloud journey, CloudHealth is the platform of choice for leading enterprises and service providers, such as Pinterest, Yelp, Dow Jones, Zendesk, Skyscanner and SHI.
- kops: helps you create, destroy, upgrade and maintain production-grade, highly available, Kubernetes clusters from the command line. AWS (Amazon Web Services) is currently officially supported, with GCE in beta support , and VMware vSphere in alpha, and other platforms planned.
Prerequisites
- When using Cloudhealth, ensure you or IT has master account access in AWS. This is required in order to properly inspect and analyze cost from AWS on any account. The master account can pull cost data from any subtending account.
- Access to the Kubernetes cluster in order to install an Cloudhealth collector.
- Deployed and well understood application, in order to ensure you can allocate the resources for analysis
- Knowledge of any services used in supporting the Kubernetes cluster beyond EC2 and VPCs.
- i.e. the Route 53 domains used in the cluster, and this will be utilized to allow url based access to the services in the cluster, and is generally not a well though of “connected” service.
- i.e. S3 buckets used to store the kops state information when managing Kubernetes.
Application analysis using Cloudhealth
Before we walk through the configuration and setup, its useful to see the value Cloudhealth provides in analyzing a kubernetes based deployment.
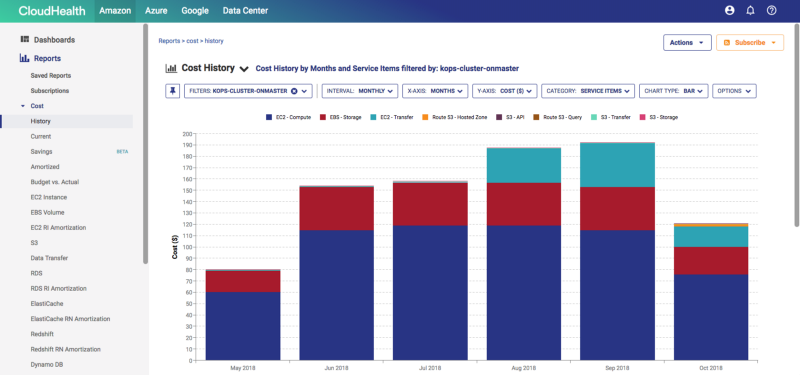
I can analyze my kops cluster (firstcluster.fitcycledev) since the time it was deployed for all the components being used by the cluster:
- EC2 (compute, network, EBS volume)cost for my 3 node cluster ( 1 master and 2 worker nodes)
- route53 costs for the domain
- S3 usage (mostly for KOPs management vs the application). This usage will be split amongst multiple clusters when more are deployed. We’re showing it here because its part of this particular deployment
Historical (past months usage)
Projected view (the next 3 months based on the past 6 months of use)
I can see that my spend is going to go up, are there any ways to optimize? Cloudhealth will make recommendations. My cluster uses the following EC2 instance types:
- m3.medium for the master
- t2.medium for the worker nodes
Potential opportunities to “rightsize” my cluster:
Cloudhealth has recommended I downgrade one of the worker nodes to a t2.small because I could achieve a $17.06 savings, due to the utilization and cost over time. The utilization does NOT warrant such a high instance type. He the opportunity to save on this particular component of the cluster.
While I can change one of the worker nodes to a smaller instance type, I know that this application is going to run for at least 1 more year. Cloudhealth allows me to analyze the opportunity to use RI instances instead of on-demand. I might want to just re-constitute the application in a “maintenance window” to Reserved Instances.
Potential opportunities to convert to Reserved Instances:
As Cloudhealth recommends for using Reserved Instances (RI):
- RI for my Masternode would save me $19/month
- RIs for each of my worker nodes would save me $28/month
- Overall saving of $559/year IF I decided to utilize reserved instances vs on-demand.
I might just do this, since I know this application will run for another year!!!
In addition to cost Cloudhealth also gives me standard usage information on my cluster through various different mechanisms.
EC2 Instance usage analysis (particularly showing #instance hours)
Some performance data: (also see Wavefront by VMware) (in this case I wanted to see the memory usage of my cluster)
Configuring Cloudhealth with the Kubernetes Cluster:
Deploying KOPS is relatively easy, the instructions can be found here:
https://github.com/kubernetes/kops/blob/master/docs/aws.md
The application used is fitcycle — found here:
https://github.com/bshetti/container-fitcycle
The configuration of the cluster and its associated resources:
- EC2 3 node cluster ( 1 m3.medium for the master and 2 worker nodes running t2.medium)
- route53 configured with a fitcycledev.xxx domain which is used by kops to setup kubernetes API access
- NO load balancers- since I’ve configured the application for nodePort vs loadBalancing with kubernetes.
- S3 usage (mostly for KOPs management vs the application). This usage will be split amongst multiple clusters when more are deployed. We’re showing it here because its part of this particular deployment
- VPC is automatically configured by KOPs when the cluster is created.
Once the application is up, you simply install the cloudhealth container collector on the Kubernetes kops cluster.
(following commands and kubernetes-collector-pod-template.yaml file are from cloudhealth)
export CHT_API_TOKEN=78347783759db01a596f42er33453345
export CHT_CLUSTER_NAME=kops-masteraccount
kubectl create secret generic --namespace default --from-literal=api-token=$CHT_API_TOKEN --from-literal=cluster-name=$CHT_CLUSTER_NAME cloudhealth-config
kubectl create -f kubernetes-collector-pod-template.yaml
Once the collector is configured, it will show up in Cloudhealth:
kop-masteraccount collector shows healthy
Next you need to build a “perspective” in cloudhealth. A perspective is a way to group various different resources into a collection. This collection is used in filtering the analysis — historical, projected, rightsizing, usage etc for the specific set of resources in the collection VS all the resources in your accounts in AWS.
The image above shows the different groups that make up my kops-cluster-onmaster perspective. In particular, I’ve selected the AWS Assets (general bucket for all EC2 and other resources), which shows the master and worker nodes in my cluster.
With this perspective, you can walk through the same analysis I reviewed earlier in this blog.
Summary
While I showed how Cloudhealth can analyze my costs on a self-deployed cluster on AWS, the same procedure can be applied to other Kubernetes deployments methods in other clouds:
- PKS on AWS
- KOPs on Azure
- etc
As long as the deployment is Kubernetes Conformant, the Cloudhealth cluster will pull the needed information.
With the analysis shows above, you can truly optimize (pre and post deployment) your production kubernetes deployments on AWS/Azure/GCP using any self-deployment installation tool set.
For more information on Cloudhealth
https://www.cloudhealthtech.com/


